世界模型定义:世界模型(World Models)是人工智能领域一个至关重要的概念,它指的是一个能够对环境或世界的状态进行表征,并预测状态之间转移的模型
核心思想:世界模型的核心思想在于赋予人工智能系统一种类似人类的“想象力”和“规划”能力
与传统AI的区别:从被动响应到主动预测:
世界模型与传统AI范式(如监督学习、强化学习)的根本区别在于其从被动响应到主动预测的转变。传统的监督学习模型,其核心任务是学习一个从输入到输出的映射函数,例如图像分类或语音识别。这些模型在处理一个输入时,并不会考虑这个输入在时间序列上的前后关系,也不会预测未来的状态。它们只是根据训练数据中学到的模式,对当前的输入做出一个判断。而世界模型则不同,它关注的是时间序列上的动态变化,致力于理解“世界为什么会这样变化”。
例如,在自动驾驶领域,传统的强化学习方法可能需要车辆在真实道路上进行数百万公里的测试,才能学会如何应对各种突发情况。而基于世界模型的方法,则可以通过学习大量的交通场景视频,在内部构建一个交通环境的模拟器,然后在这个模拟器中进行规划和训练,从而大大减少在真实道路上的测试里程和风险。
关键要素:观测、状态、行动与潜在变量
杨立昆对世界模型的定义中,包含了几个不可或缺的关键要素,它们共同构成了世界模型的核心功能。这些要素分别是观测(Observation)、状态(State)、行动(Action)和潜在变量(Latent Variable) 。
观测(x(t)) :这是智能体从环境中接收到的原始感官数据,例如摄像头捕捉到的图像、麦克风接收到的声音等。观测数据通常是高维度的,并且可能包含噪声和无关信息。世界模型的第一步就是处理这些观测数据,提取出有用的信息。
状态(s(t)) :状态是对世界在某一时刻的完整描述。它不仅仅包括当前的观测,还可能包含一些无法直接观测到的信息,例如物体的速度、隐藏的目标等。世界模型的目标之一就是维护一个对世界状态的准确估计。这个状态估计是智能体进行决策和规划的基础。
行动(a(t)) :行动是智能体可以执行的操作,例如移动、抓取、说话等。世界模型需要能够预测不同行动可能带来的后果。通过模拟不同行动序列的结果,智能体可以选择最优的行动方案来达到其目标。
潜在变量(z(t)) :这是杨立昆定义中一个非常关键的要素。潜在变量代表了那些无法被观测到的、但对世界演化有重要影响的信息。例如,一个球的飞行轨迹不仅取决于它的初始位置和速度,还可能受到风的影响。风的大小和方向就是潜在变量。由于我们无法直接观测到风,所以我们将其建模为一个随机变量。通过从某个分布中采样潜在变量,世界模型可以生成一组合理的未来预测,从而处理现实世界中的不确定性 。
核心技术架构:V-M-C模型
V:视觉模型:VAE
M:记忆模型:RNN LSTM
C:控制器:Policy Network
典型优势
- 样本效率高:可在模型内大量“虚拟交互”,减少对真实环境的昂贵/危险探索。
- 可规划性与长视野:显式预测未来,天然适用于长时序任务与稀疏奖励。
- 泛化与迁移:学习到的世界规律在任务变化(目标、起点、奖励)时可复用,减少从零学习成本。
- 安全性与可控性:在想象空间先验验证策略,规避高风险动作;可加入约束与守卫条款(shields)。
- 可解释性提升(相对无模型方法):对象-中心/因果-结构化世界模型使故障分析与反事实推理更直接。
- 与多模态/语言的自然融合:将语言/符号作为高层意图或约束,与低层动力学耦合,支持端到端具身指令执行。
《Semantic Communications with World Models》
Authors: Peiwen Jiang, Jiajia Guo, Chao-Kai Wen, Shi Jin, Jun Zhang
Categories: eess.IV,cs.IT,math.IT
Date: 10/30/2025
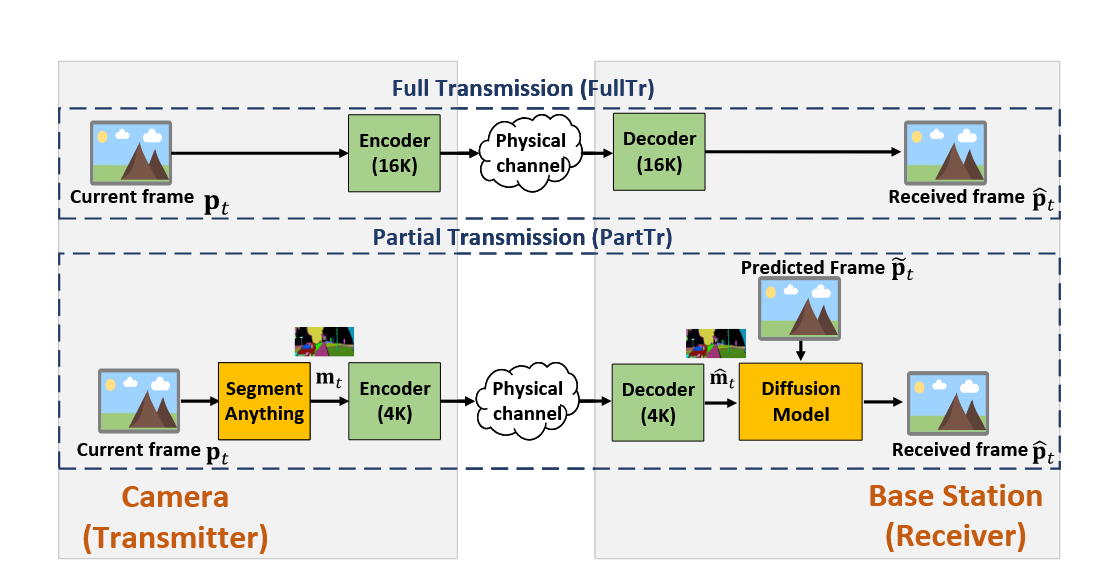
论文提出一种WFM 赋能的语义视频传输框架:用世界模型根据“当前已传图像 + 文本引导”预测后续多帧,当预测质量足够好时跳过无线传输以节省带宽;当预测逐步劣化时,利用轻量反馈与可选传输机制自适应地触发纠正与更新。该思路旨在在极低带宽与时变信道下维持任务/感知指标,同时显著降低传输开销。
把 WFM 用作“内部未来帧生成器”
在基站侧部署 WFM(示例采用 CogVideoX),以“接收的当前帧 + 文本描述(如相机运动状态)”为条件,生成后续若干帧,从而在若干时隙内免传。文本只更新相机状态,几乎不占带宽。
设计两种“可选前向传输”以配合 WFM 预测
- FullTr(整帧传输):必要时发送整帧作“重置”,但带宽最高、对信道最敏感。
- PartTr(分部传输):先用 SAM 生成语义分割掩码并低开销发送,接收端用条件扩散模型结合“WFM 预测帧 + 掩码”进行修复,以较小带宽“拉回”预测误差。
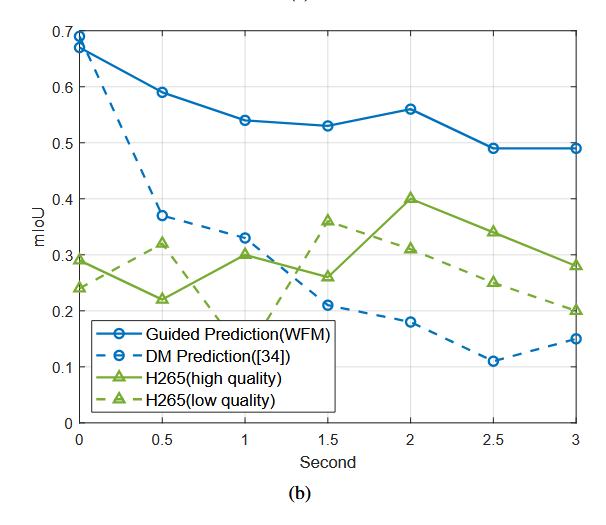
实验:
KITTI 数据集,对比基线为AV1 视频编码 + LDPC 信道编码。除 PSNR 外,采用 LPIPS、mIoU、δ>1.25\delta>1.25δ>1.25(深度精度阈值指标)与 DreamSim,覆盖感知质量、语义分割与深度估计。
消融实验和DM比较: