本文参考:Denoising Diffusion GANs阅读笔记
动机:
当下的生成学习框架中“高采样质量”、“模式覆盖与多样性”、“快速低计算开销的采样“这三点无法同时满足
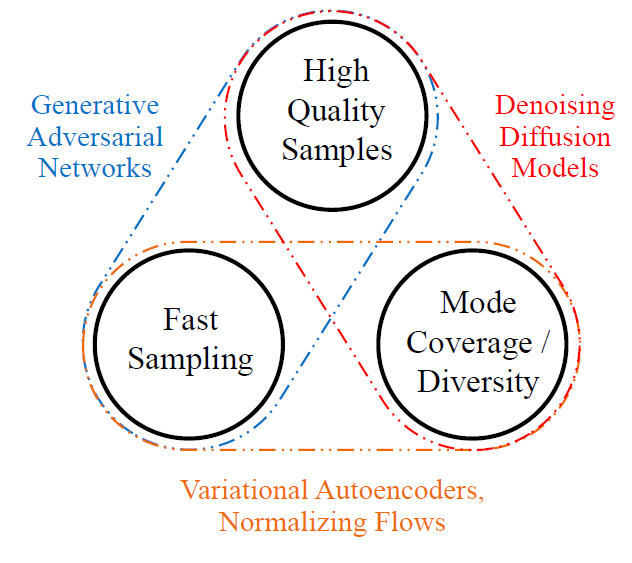
可以看到Gan在采样质量和速度上做的比较好,但在多样性上差一些;而DDPM在高采样质量的前提下还拥有了多样性,但是采样速度是比较慢的。
为什么DDPM的采样步数多呢?在Denoising Diffusion GANs阅读笔记中有明确的公式推导,我简单概括一下,由于DDPM把正向扩散定义为逐步加零均值高斯噪声的马尔可夫过程,当每一步的方差 βt足够小时,可由贝叶斯/局部近似得到:反向条件分布也可被高斯很好地逼近,这样建模反向采样就很方便。
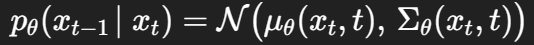
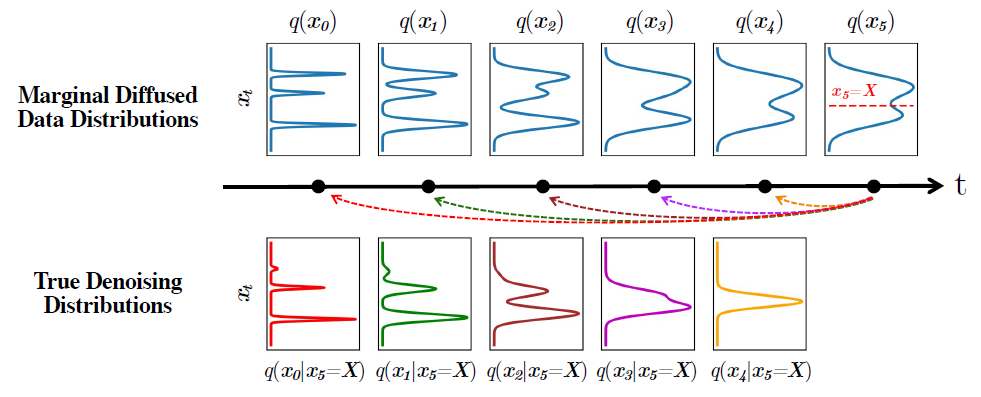
下面这张图的第一行从左往右,展示了随着给原数据加噪,数据的概率分布逐渐倾向于高斯分布,第二行从右往左,分别展示了跨越一步、二步、一直到五步的去噪条件分布,可以看到随着去噪的步数增加,从高斯分布逐渐变成多模态的复杂分布,不利于建模求解。
Denoising Diffusion GAN的设定
为了减少采样步数,这篇论文做出假设,总步数T更小(<=8)。每个扩散步的噪声调度更大,具体的GAN训练过程见原回答,我主要总结一下如何建模去噪的多模态分布。作者指出,原始DDPM论文没有明说,但实际上可以解读为如下过程:先使用去噪模型预测x0 ,再用已知的xt和预测出的x0来从后验分布中采样得到xt-1.
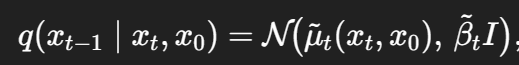
其中
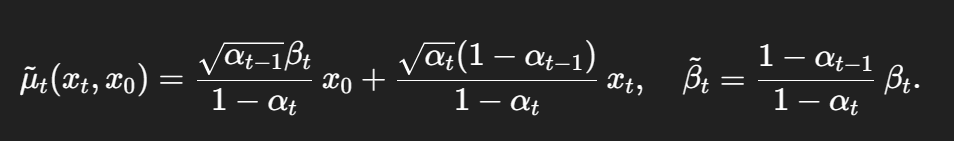
由于噪声调度大,反向不满足马尔可夫,x0现在不能直接由xt估算,所以给x0加上了一个随机扰动来“假装”估算了x0,所以本质上扩散模型只是用来稳定GAN的训练,对扩散模型本身没有帮助。
补看了,因为对我的科研没啥帮助

